
給 AI 超能力?Superpowers 的設計與取捨
有在用 AI 寫程式的朋友們,不管是用哪一家的都或多或少遇過這樣的情況,就是我們跟 AI 描述一個需求,還沒仔細討論完 AI 就直接動工了然後跟你說做好了,結果一跑發現根本不能用,或是 AI 說 Bug 修好了但測試後發現只是換另一種方式壞掉。
這不是 AI 不聰明,而是目前的 LLM 還缺乏「紀律」。AI 不一定每次都會先想清楚再動手,不一定每次都會寫測試,不一定會在完成之前真的跑一遍測試。這些在人類工程師身上多年養成的習慣,AI 並不會自動具備。不過也不是每個工程師都有這些習慣就是了... :)
好啦,這不是重點,重點是我想跟大家介紹一套名為 Superpowers 的工作流規範,它在 GitHub 上有將近 3 萬顆星星,Superpowers 這個專案名字取的雖然有點浮誇,不過它的目的是希望幫助 AI 建立寫程式的紀律。這不是什麼軟體或函式庫,這是一套給 AI 看的工作流規範。你可以把它想成是給 AI Agent 的員工手冊,裡面寫了「做 XXX 之前要先 YYY」、「完成 ZZZ 之後要怎樣驗證」之類的規定。
這篇文章不是教你怎麼用 Superpowers,而是想跟大家介紹它的設計理念和規則。我這幾天仔細看了一下文件之後發現這套東西的設計很有趣,如果讀完文件之後應該對「如何指導 AI 寫程式」會有更清楚的認識。當然,如果你想直接用它也沒問題,直接到 Superpowers 的 GitHub 頁面就能看到怎麼安裝跟使用方式。
文章有點長,怕大家沒耐心看完所以一樣先講結論:
Superpowers 用 15 個 Skills 建立了一套完整的 AI 開發工作流,從需求釐清到分支合併都有對應的規範。它的設計有點激進,不是「你應該」而是「你必須」,而且針對 AI 可能找的各種藉口預先堵死。不一定適合所有人,但即使不用,讀一遍也能學到怎麼更有效地指導 AI 寫程式。
架構
Superpowers 的核心是 15 個 Skills,每個 Skill 都是一份 Markdown 文件,描述特定情境下應該遵循的流程。如果不知道 Skills 是什麼的話,可參閱「Claude Code Skills:讓 AI 變身專業工匠」文章介紹。
除了 skill 之外,有一個名為 SessionStart 的 hook 會在每次對話開始時執行,把 using-superpowers 這個入門 skill 注入到對話裡,讓 AI 從一開始就知道自己有這些規範可以參考。Hook 是 Claude Code 的一個功能,讓你可以在特定事件發生時自動執行特定指令,例如對話開始、工具被呼叫、或對話結束時,詳細說明可以參考官方文件。
這些 skill 形成一個完整的開發工作流,從需求釐清、設計審查、計畫撰寫、測試驅動開發、程式碼審查,一直到分支合併。每個環節都有對應的 skill 來規範該怎麼做。
動手之前的蘇格拉底
brainstorming 這個 skill 要求在開發新功能之前,會先採用「蘇格拉底式(Socratic)」的對話式提問來釐清需求,例如:
- 一次只問一個問題
- 能用選擇題就不要用開放式問題
- 不要連珠炮式地丟出一堆問題讓使用者應接不暇
這如果搭配 Claude Code 的 AskUserQuestion 工具還滿好用的。當 AI 認為自己理解需求之後,接著會用 200 ~ 300 字的文字來撰寫設計方案,每個段落結束後都會跟使用者確認「這樣對嗎?」如果使用者說不對,就會再回去修改。這個設計的用意是避免一次把整個設計甩出來,使用者看都懶得看就按同意,這是個滿聰明的做法,設計者都知道其實大家都沒在看,滿懂人性的 :)
在探索不同方案時,skill 要求提出 2 到 3 個不同的做法,說明各自的取捨,然後給出推薦選項和理由。這裡有個叫做 YAGNI ruthlessly 的原則,YAGNI 是 You Ain't Gonna Need It 的縮寫,意思是設計階段就要積極砍掉不必要的功能,不要等到實作時才發現做了一堆用不到的東西。
原始碼裡的關鍵原則:
One question at a time - Don't overwhelm with multiple questions
YAGNI ruthlessly - Remove unnecessary features from all designs
寫計畫:假設執行者什麼都不懂
writing-plans 這個 skill 對計畫的要求非常嚴格。它的前提假設是執行這份計畫的人對專案一無所知,品味跟判斷力都欠佳(咦?),而且還不喜歡寫測試。在這個假設下,計畫必須寫得極度詳細,不能有任何模糊地帶。
每個任務都被拆成 2 ~ 5 分鐘可以完成的小步驟。寫一個失敗的測試是一個步驟,跑測試確認它失敗是另一個步驟,寫最小的程式碼讓測試通過又是另一個步驟。這種拆法有點囉嗦,但好處是每個步驟都有明確的完成標準,不會出現做到一半不知道該不該繼續的情況。
每個步驟都要包含完整的程式碼,不能寫加上「適當的測試」這種模糊描述(我就很常這樣寫)。檔案路徑要寫死,執行的指令要寫死,預期的輸出也要寫死。這意味著一個完全不了解專案的人,或者一個新開的 AI session,都可以照著步驟做完,不需要額外的解釋。
原始碼裡的關鍵原則:
Write comprehensive implementation plans assuming the engineer has zero context for our codebase and questionable taste. Document everything they need to know.
Each step is one action (2-5 minutes)
測試驅動開發
TDD 不是什麼新名詞了,test-driven-development 這個 skill 把 TDD 定義得很嚴格,而且明確說違反規則的字面意義就是違反規則的精神,堵住了「我遵循的是 TDD 的『精神』」這種藉口。核心規則只有一條:
沒有先寫測試就不能寫 code!
如果你先寫了 code 再補測試,正確的做法是刪掉那段 code,從測試開始重新來過。不是把它留著當參考,也不是一邊看著它一邊再補寫測試,是真的刪掉,假裝它從來不存在。我必須承認我很懶,我自己做不到這一點。
紅綠重構(Red-Green-Refactor)的循環是先寫一個會失敗的測試,跑一次確認它真的失敗,然後寫最小的 code 讓它通過,跑一次確認它通過,最後再進行重構。每個步驟都要實際執行,不能跳過。如果測試一寫完就通過了,表示你測的是已經存在的行為,這個測試沒有意義,要重新想想你到底想測什麼。
這個 skill 花了很大的篇幅處理各種「藉口」,很值得花點時間閱讀。例如:
- 說「太簡單不需要測試」,它會告訴你簡單的 code 也會出錯,寫測試只要 30 秒。
- 說「我已經手動測試過」,它會說手動測試不系統、沒記錄、無法重跑。
- 說「測試後寫也能達成同樣目標」,它會解釋測試前問的是「這個東西應該做什麼」,測試後問的是「這個東西做了什麼」,答案完全不同。
- 說「刪掉 X 小時的工作太浪費」,它會說這是沉沒成本謬誤,保留未經驗證的程式碼才是真正的浪費。
還有一個 testing-anti-patterns 文件專門講測試的常見錯誤。比如「測試 mock 的行為而不是真正的程式碼」,你寫了一個測試檢查 mock 存在,這證明什麼?可能什麼都沒證明到,你只是在測試你的 mock 設定正確。又比如「在正式程式碼裡加入只有測試會用的方法」,這會污染正式程式碼,而且萬一有人在正式環境呼叫那個方法就麻煩了。
原始碼裡的關鍵原則:
NO PRODUCTION CODE WITHOUT A FAILING TEST FIRST
Write code before the test? Delete it. Start over.
Violating the letter of the rules is violating the spirit of the rules.
理性化預防表格節錄:
| 藉口 | 現實 |
|---|---|
| Too simple to test | Simple code breaks. Test takes 30 seconds. |
| I'll test after | Tests passing immediately prove nothing. |
| Tests after achieve same goals | Tests-after = "what does this do?" Tests-first = "what should this do?" |
| Deleting X hours is wasteful | Sunk cost fallacy. Keeping unverified code is technical debt. |
完整內容:test-driven-development/SKILL.md
系統性除錯,不要亂猜
systematic-debugging 這個挺好用的,我用它抓過幾個 Bug。這個 skill 會把除錯分成四個階段,而且要求必須完成前一個階段才能進入下一個。
第一階段:根因調查(Root Cause Investigation)
仔細讀錯誤訊息,不是看一眼就跳過。要能穩定重現問題,不能重現就不要猜。要檢查最近改了什麼,用 git diff 看看有沒有可疑的變更。如果系統有多個元件,要在每個元件的邊界加上 log,搞清楚資料在哪裡出問題。
第二階段:模式分析(Pattern Analysis)
找出類似的正常運作的程式碼,比較哪裡不一樣。如果在實作某個 pattern,要把參考資料讀完,不是讀一半就開始動手。
第三階段:假說與測試(Hypothesis and Testing)
提出一個具體的假說,寫下來,然後做最小的修改來驗證。就像做科學實驗的實驗組跟對照組一樣,一次只改一個變數,不要同時改好幾個東西然後說「好像好了」。如果假說被推翻了,就提出新的假說,不要在錯誤的方向上繼續加 code。
第四階段:實作(Implementation)
先寫一個能重現問題的測試,然後修復,確認測試通過。如果修了三次還沒好,就要停下來問這個架構本身是不是有根本問題?三次失敗表示你可能不是在修 Bug,而是在跟原本的設計打架,或是已經進入鬼打牆的狀態了。
這個 skill 還附帶幾個技術文件:
defense-in-depth講的是當你修好一個 bug 之後,要在每一層都加上驗證,讓這個 bug 結構上不可能再發生。不是只在入口加一個檢查就算了,而是在 API 邊界、業務邏輯、環境層面都加上防護。condition-based-waiting講的是不要猜測需要等多久,要等到你真正在意的條件成立為止。例如:
// 不好:猜測需要等多久
await new Promise((r) => setTimeout(r, 50))
const result = getResult()
expect(result).toBeDefined()
// 好:等到條件成立為止
await waitFor(() => getResult() !== undefined)
const result = getResult()
expect(result).toBeDefined()
第一種寫法猜 50 毫秒應該夠了,但在 CI 機器或負載高的時候可能不夠,測試就會飄忽不定。第二種寫法直接等到結果出現,不管實際花多久。
root-cause-tracing講的是怎麼從錯誤點往回追溯,找到問題的源頭。
原始碼裡的關鍵原則:
NO FIXES WITHOUT ROOT CAUSE INVESTIGATION FIRST
ALWAYS find root cause before attempting fixes. Symptom fixes are failure.
If 3+ Fixes Failed: Question Architecture
理性化預防表格節錄:
| 藉口 | 現實 |
|---|---|
| Issue is simple, don't need process | Simple issues have root causes too. Process is fast for simple bugs. |
| Emergency, no time for process | Systematic debugging is FASTER than guess-and-check thrashing. |
| I see the problem, let me fix it | Seeing symptoms ≠ understanding root cause. |
| One more fix attempt (after 2+ failures) | 3+ failures = architectural problem. Question pattern, don't fix again. |
完整內容:systematic-debugging/SKILL.md
驗證優先,說完成之前先跑一遍
verification-before-completion 這個 skill 處理的是 AI 常見的壞習慣,就是還沒驗證就說完成了。它開頭就說「宣稱工作完成但沒有驗證,是不誠實,不是有效率」。
規則也很簡單,就是在說任何「完成」、「修好了」、「測試通過」之類的話之前,必須先跑對應的驗證指令,讀完整的輸出,確認結果符合宣稱。不能說「應該可以」,不能說「我有信心」,不能說「看起來對」。要有證據,不是有感覺。
這個 skill 列出了各種宣稱和對應的驗證方式。說測試通過,要有測試指令的輸出顯示 0 個失敗。說 build 成功,要有 build 指令的 exit code 是 0。說 bug 修好了,要重新測試原本的症狀確認它不再出現。說 subagent 完成任務了,要檢查 git diff 確認有實際的變更,不能只相信 subagent 回報的結果。
它還列出一些可能的警告訊息,告訴你什麼時候該停下來:
- 如果你發現自己在用「應該」、「大概」、「似乎」這些詞,停停停!
- 如果你在說「完成」之前感到滿意或興奮,停停停!
- 如果你想說「這次就不驗證了」,停停停!
這些都可能是正在跳過驗證的信號。原始碼裡的關鍵原則:
NO COMPLETION CLAIMS WITHOUT FRESH VERIFICATION EVIDENCE
Claiming work is complete without verification is dishonesty, not efficiency.
Evidence before claims, always.
通關檢查:
1. IDENTIFY: What command proves this claim?
2. RUN: Execute the FULL command (fresh, complete)
3. READ: Full output, check exit code, count failures
4. VERIFY: Does output confirm the claim?
5. ONLY THEN: Make the claim
完整內容:verification-before-completion/SKILL.md
兩階段審查,先看規格再看品質
subagent-driven-development 這個 skill 定義了一個滿好玩的審查流程,就是每個任務完成後要經過兩道審查,而且順序不能對調。
第一道是規格符合性審查(Spec Compliance Review),開一個 Subagent 檢查程式碼是否完全符合規格,不多不少。多做了不該做的事是問題,少做了該做的事也是問題。這道審查的重點不是看程式碼好不好,而是看「這是不是我們要的東西」。
第二道是程式碼品質審查(Code Quality Review),只有在規格審查通過之後才會執行。這道審查看的是測試覆蓋率、程式碼架構乾不乾淨、可維護性這些東西。
把這兩種審查分開是有道理的。「code 寫得很好但不是我們要的」是很常見的問題,先確認方向對了再談品質,可以避免花大量時間打磨一段根本不該存在的程式碼。如果審查者發現問題,實作者要修復,然後重新審查。不是修完就算了,要確認審查者這次認可才能繼續。
原始碼裡的關鍵原則:
Fresh subagent per task + two-stage review (spec then quality) = high quality, fast iteration
Start code quality review before spec compliance is ✅ (wrong order)
不要踩這些坑:
- Skip reviews (spec compliance OR code quality)
- Accept "close enough" on spec compliance
- Let implementer self-review replace actual review (both are needed)
完整內容:subagent-driven-development/SKILL.md
收到審查意見
receiving-code-review 這個 skill 處理的是收到審查意見之後該怎麼反應。它有一個很直接的規定,就是不准說「你說得對!」、「好建議!」這類「表演性(performative)」的贊同。
AI 還滿擅長講這種提供滿滿情緒價值但沒有什麼實質幫助的話,這些話聽起來很有禮貌而且可能還滿爽的,但這些是情緒表演,不是技術回應。說「你說得對」然後開始改 code,跟直接改 code 相比,前者多了一個沒有資訊量的步驟。而且更糟的是,有時候審查者其實是錯的,但你因為不想顯得不配合就照做了。
這個 skill 要求收到審查意見之後要先理解、再驗證、再評估、最後才回應。理解是用自己的話複述對方的要求,確認你沒有誤解。驗證是檢查這個建議在這個 codebase 裡是否正確,會不會破壞現有功能。評估是判斷這是不是一個好建議,還是審查者缺乏 context 所以提出了不適用的建議。
如果審查者的建議是錯的,要用技術理由推回去,而不是因為不好意思就照單全收。如果因為某些原因不方便直接拒絕,skill 裡甚至提供了一個「暗號」:
Strange things are afoot at the Circle K
「便利商店那邊不太對勁」蛤?這什麼?這句話很有趣,經查這是出自 1989 年的一部老電影 Bill & Ted's Excellent Adventure,Circle K 是美國的連鎖便利商店,台灣的 OK 便利店就是它的加盟商。選這句大概是因為夠冷門,在我們一般的對話不會出現,一出現就知道這是暗號,就像聊著聊著突然來一句「今晚打老虎」一樣。意思是讓人類開發者知道你有話想說但不方便說。這可能是少數教 AI 處理職場人際關係的技術文件。如果是自己推回錯了,也不用長篇道歉,直接說「你是對的,我查了 X 確認是 Y,現在來修」就好。
原始碼裡的關鍵原則:
Code review requires technical evaluation, not emotional performance.
Verify before implementing. Ask before assuming. Technical correctness over social comfort.
禁止的回應:
- "You're absolutely right!"
- "Great point!" / "Excellent feedback!"
- "Let me implement that now" (before verification)
正確回應模式:
- Restate the technical requirement
- Ask clarifying questions
- Push back with technical reasoning if wrong
- Just start working (actions > words)
完整內容:receiving-code-review/SKILL.md
寫 Skill 本身也是 TDD
writing-skills 這個 skill 講的是怎麼寫新的 skill,它的核心觀點是寫 skill 就是 TDD,只是對象從程式碼變成文件。
流程是先設計一個壓力測試場景,開一個 subagent 在沒有這個 skill 的情況下執行,記錄它會怎麼做、會用什麼藉口繞過規則。這是「看測試失敗」的步驟。然後寫 skill 來解決這些具體的問題。再開一個 subagent 在有 skill 的情況下執行同樣的場景,確認它這次遵守規則。這是「看測試通過」的步驟。如果 subagent 找到新的繞過方式,就加入對應的防堵措施,然後重新測試。
這個 skill 強調要針對 AI 會用的藉口來設計防堵措施。不是寫「請遵守 TDD」就好了,而是要預想 AI 會說「這次不一樣」、「這個太簡單」、「我已經手動測試過」這些話,然後在 skill 裡明確反駁每一個藉口。
它還提到一個測試時發現的問題,如果 skill 的描述欄位總結了 skill 的工作流程,AI 可能會只讀描述就開始做,不讀完整內容。比如描述寫「每個任務之間做 code review」,AI 就只做一次 review,即使 skill 內文明確說要做兩次。所以描述欄位應該只寫「什麼時候用這個 skill」,不要寫「這個 skill 做什麼」。
原始碼裡的關鍵原則:
- Writing skills IS Test-Driven Development applied to process documentation.
- NO SKILL WITHOUT A FAILING TEST FIRST
- If you didn't watch an agent fail without the skill, you don't know if the skill teaches the right thing.
TDD 對照表:
| TDD 概念 | Skill 創作 |
|---|---|
| Test case | Pressure scenario with subagent |
| Production code | Skill document (SKILL.md) |
| Test fails (RED) | Agent violates rule without skill |
| Test passes (GREEN) | Agent complies with skill present |
| Refactor | Close loopholes while maintaining compliance |
整體工作流程
把上面這些 skill 串起來,一個典型的開發流程可能會像這樣:
brainstorming
→ writing-plans
→ using-git-worktrees
→ subagent-driven-development
→ finishing-a-development-branch
使用者描述一個想法,brainstorming skill 啟動,AI 開始問問題釐清需求。問完之後提出幾個可能的方案,使用者選一個,AI 把設計寫成文件。using-git-worktrees skill 啟動,在一個新的 worktree 裡建立隔離的工作環境。writing-plans skill 啟動,把設計拆成一堆小任務,每個任務都有完整的指令和程式碼。
subagent-driven-development skill 啟動,對每個任務派一個 subagent 去做,做完之後派另外兩個 subagent 做規格審查和品質審查。test-driven-development skill 在每個 subagent 裡面運作,確保他們先寫測試再寫 code。
所有任務做完之後,finishing-a-development-branch skill 啟動,跑完整的測試,然後問使用者要合併、開 PR、保留分支、還是丟掉這些變更。
搭配 OpenSpec 留下規格紀錄
使用 Superpowers 的工作流程有個小問題,就是所有東西都在對話裡,session 結束就沒了(其實應該是會存在 ~/.claude 目錄裡,但不好找)。這對於長期維護的專案來說不太方便。如果你想留下正式的規格文件和變更紀錄,可以搭配 OpenSpec 一起服用,詳細使用方式可參閱「OpenSpec 讓 SDD 變簡單的三個指令」文章介紹。
簡單的說,OpenSpec 是一個 SDD(Spec-Driven Development)工具,核心概念是用 proposal 來描述「要做什麼」和「為什麼」,用 spec delta 來描述「會影響哪些現有規格」,完成後再 archive 留下紀錄。我自己最近的搭配使用流程大概是這樣:
brainstorming(釐清需求,不一定需要,比較複雜任務才需要)
→ openspec proposal(正式化規格,產生高階 tasks.md)
→ writing-plans(把 tasks.md 的內容展開成更細的執行步驟,但這不一定需要)
→ openspec apply(開始實作)
→ openspec archive(歸檔)
OpenSpec 的 tasks.md 是高階任務清單,如果任務本身不複雜,直接照著做就好。如果某個任務比較麻煩,再用 writing-plans 展開成細步驟。不用每個任務都展開,看情況決定。
也不是每次都要走完整流程,例如需求本來就清楚的話,brainstorming 這個步驟也可以跳過。修 Bug、改錯字、調整設定檔這些小事,說不定連 proposal 都不用開,直接動手改就好。
我最近還為 OpenSpec 做了個簡單的 GUI 介面:
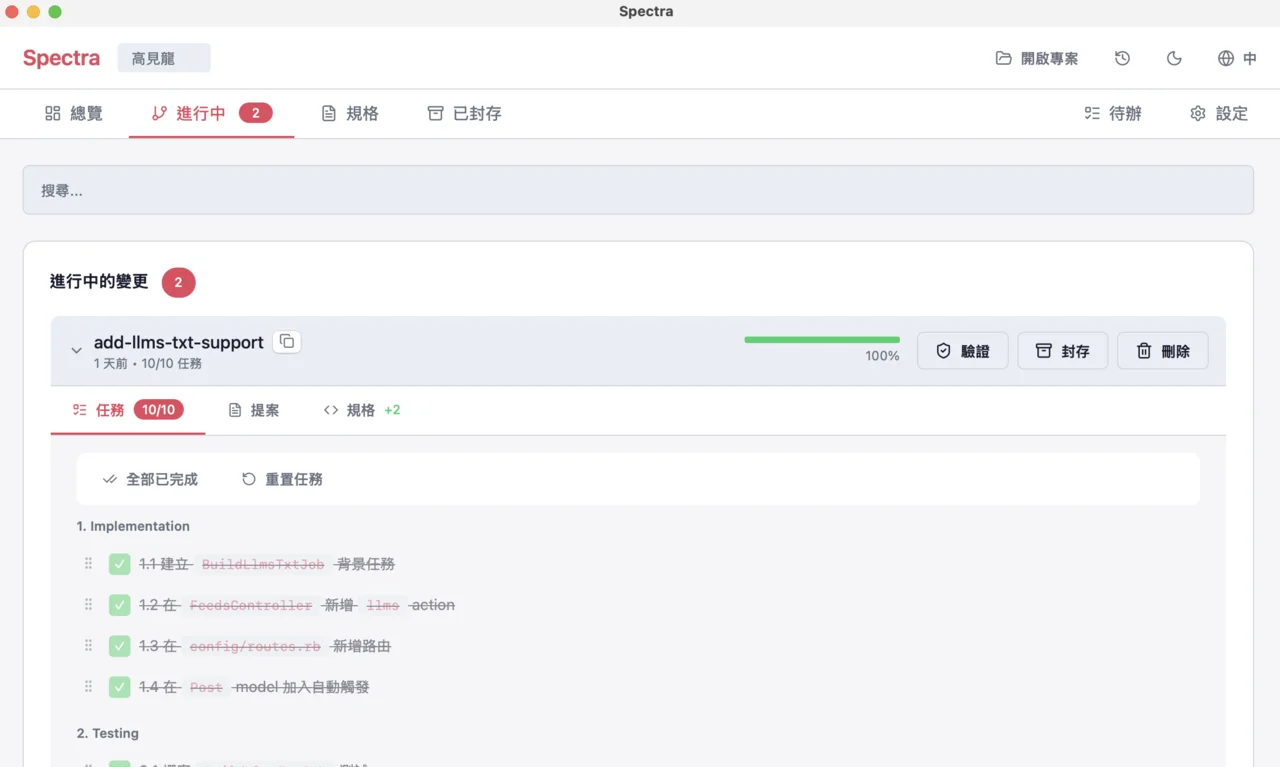
目前還在打磨以及公司內部試用階段,但已經可以用來瀏覽或修改 proposal、spec delta、archive,待更成熟一些再丟出來給大家玩 :)
設計上的取捨
讀完這些 skill 之後,有幾個設計決策我覺得很有趣也印象深刻。
第一個是它採取強制而非建議的立場。大多數開發指南都用「你應該」這種語氣,Superpowers 則直接說「沒有先寫測試就不能寫 code」、「沒有驗證就不能說完成」。它甚至有一句「違反規則的字面意義就是違反規則的精神」,堵住了「我遵循的是精神」這種藉口。這種攻擊性的寫法在技術文件裡很少見,但仔細想想,AI 確實需要這種明確的規則,而不是模稜兩可的建議。
第二個是它大量使用理性化預防表格。每個重要的 skill 都會列出一堆常見的「藉口」,然後逐一反駁。這不是在教你道理,而是在堵漏洞。AI 很會找藉口,你不把這些藉口堵死,它就可能會不小心繞過去。
第三個是每個步驟都要有驗證。不是做完就算了,而是做完之後要確認真的做對了。寫測試要跑一次確認它失敗,寫 code 要跑一次確認測試通過,修 bug 要重新測試症狀確認它消失了。這種頻繁驗證的設計增加了步驟數量,但也大幅減少了「以為好了其實沒好」的情況。
第四個是任務的原子性。每個任務都被設計成可以獨立執行,不依賴前面任務的 context,不依賴執行者的判斷。這意味著可以派一個新的 subagent 來做,不用擔心它不知道前面發生了什麼事。
看起來很美好,但好像也有一些限制跟問題...
限制和問題
最明顯的問題是它完全依賴 AI 的自律。整個系統都是文件,沒有任何技術手段強制執行。AI 可以選擇遵守,也可以選擇跳過。Release notes 裡有提到一個失敗模式,就是 AI 會想「我知道那是什麼意思」然後直接開始工作,根本不載入 skill。即使 skill 裡寫得很明確,AI 還是可能很「理性」的繞過去。
成本是另一個考量。例如 subagent-driven-development 每個任務會開 3 個 subagent,分別是實作者和兩個審查者。每個 subagent 都是完整的新 session,無法重用之前的 context。如果你的專案有 50 個任務,Token 燒的速度還滿快的。
對於大型功能,計畫檔案會變得很龐大。幾百個步驟的計畫很難修改,使用者在執行中途想改方向會很痛苦。而且即使用了 subagent,任務執行還是一個一個來的,不是真正的平行處理。
Superpowers 也會假設你的開發環境都搞定了,例如要安裝並設定好 Git、專案要有測試套件、build 和 test 指令也都設定好了。對於沒有遵循慣例的專案,Superpowers 的 skill 可能會失效或需要另外調整。
還有最重要的一點,這點目前可能還無解,就是雖然 Superpowers 立意良善,不斷強調 YAGNI 原則,不要過度設計,只做需要的東西就好,但偏偏它自己並沒有機制來強制這一點,最終還是得靠 AI 和開發者的紀律。因為教你避免過度設計的系統,本身可能就是一種過度設計。
適合場景?
Superpowers 不是萬靈丹,如果你的專案需要高品質的程式碼,願意花時間在審查和驗證上,而且是長期維護的專案,那這套系統可以幫你「建立紀律」。但如果你只是想快速 Vibe 個原型出來試試水溫,或者寫個一次性的腳本,這套流程反而會拖慢開發時程。因為每個任務都要經過設計、計畫、實作、審查、驗證這些步驟,對於簡單的事情來說是用牛刀在殺小雞。
如果你的團隊已經有成熟的開發流程,可能也不需要這套東西。它的價值在於幫 AI 建立人類工程師已經具備的習慣,如果你有其他方式達成這個目標,那也不一定要用它。反正,如果團隊剛開始用 AI 寫程式,還沒有建立起良好的工作流程,Superpowers 可以當作一個起點,幫助你快速建立起紀律。有點像當年的 Git Flow,雖然不見得是最適合每個團隊的 flow,但它提供了一個具體的框架,讓大家可以根據團隊的需求調整成適合的版本。
小結
Superpowers 的核心是 AI 需要紀律,而紀律需要明確的規則,不能只是模糊的建議。它用一種相當激進的方式來強制這些規則,不給 AI 任何理性化的空間。每個 skill 都假設 AI 會試圖繞過,預先堵住各種藉口。
不過,這種方法是否有效,還是取決於 AI 是否真的會遵守。目前沒有技術手段可以保證這一點,只能靠提示工程和反覆的測試,當然還有人類工程師的監督。從 release notes 來看,作者不斷調整提示詞,試圖堵住 AI 繞過規則的漏洞,有點像在玩打地鼠的遊戲,堵了這邊又從那邊冒出來。
對我來說,這套 Skills 最有價值的部分不是它的具體規則,而是系統化地思考了 AI 軟體開發應該遵循什麼流程。即使不用這些 Skills(事實上我也只用其中幾項而已),讀一遍也能對「如何指導 AI 寫程式」有更清楚的認識。特別是那些理性化預防表格尤其值得參考,它們記錄了 AI 在實際開發中會找的各種藉口,這些經驗可能比任何理論都實用。
工商服務
6 小時從零完成一個前後端專案,不背語法、不用複雜的 Prompt,教你怎麼用 Claude Code 搭配 SDD 流程,系統化地指揮 AI 寫出能驗收的程式。實體場已售完,3/22 線上場還有名額!








